
This evening I published another hundred books to FluidDB. This time it was a list of the 100 best-selling books of the last 12 years, as published by the ever-wonderful Guardian Data Store. I published them as a table, mostly using the conventions documented in this post. If you’re using a modern browser (almost anything other than Internet Explorer) you can see a visualization of the FluidDB object for the table at abouttag.com/butterfly/about/table:bestsellers-1998-2010 and the best-selling book (Dan Brown’s The Da Vinci Code, depressingly) at abouttag.com/butterfly/about/book:the da vinci code (dan brown).
There’s a tag on each book that hyperlinks to the next, so you you could even click through all hundred if you really wanted.
So What?¶
Why should you or anyone else care that I’ve published this data to FluidDB? After all, the Guardian made the data available on Google docs, so anyone can do anything with it anyway. What’s the benefit of having it in FluidDB? I’m going to try to show a few things that might convince you there’s something interesting about putting this sort of data in FluidDB.
1. Query¶
The most obvious thing is that you can query data in FluidDB from anywhere with internet access without even having an account. For example, the query to find the best-selling book from the list in FluidDB is this:
miro/bestsellers-1998-2010/rank = 1
You can issue this query from anything that can talk to FluidDB and it should return the object corresponding to The Da Vinci Code, by Dan Brown. Here are a few ways of doing just that.
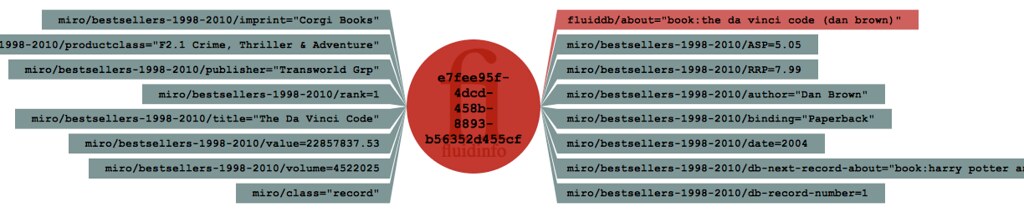
You can use the FluidDB Explorer and just paste the query into the query box. It should locate the object (identifying it by its about tag, which is book:the da vinci code (dan brown) and also by its FluidDB ID, which is e7fee95f-4dcd-458b-8893-b56352d455cf. If you then click on either the about tag or the object ID, the explorer will give you a list of tags on the object, and tell you there are too many to show (which isn’t really true). If you then click ‘Load all tag values’ it will get them and show them to you.
You can use my python library fdb, which has a command line tool with it and type:
fdb show -q 'miro/bestsellers-1998-2010/rank = 1' /miro/bestsellers-1998-2010/title /miro/bestsellers-1998-2010/authorThis produces the following output:
1 object matched Object e7fee95f-4dcd-458b-8893-b56352d455cf: /miro/bestsellers-1998-2010/title = "The Da Vinci Code" /miro/bestsellers-1998-2010/author = "Dan Brown"You can use curl at the command line (which is a utility installed on most systems by default) and type
curl 'http://fluiddb.fluidinfo.com/values?query=miro/bestsellers-1998-2010/rank%3D1&tag=miro/bestsellers-1998-2010/title&tag=miro/bestsellers-1998-2010/author'which produces:
{ "results": { "id": { "e7fee95f-4dcd-458b-8893-b56352d455cf": { "miro/bestsellers-1998-2010/author": {"value": "Dan Brown"}, "miro/bestsellers-1998-2010/title": {"value": "The Da Vinci Code"}} } } }(I’ve reformatted this slightly, but otherwise this is the exact output from FluidDB.).
You could even just use the query directly in your browser’s URL bar. Pasting the following into the address bar should work in almost all browsers
http://fluiddb.fluidinfo.com/values?query=miro/bestsellers-1998-2010/rank%3D1&tag=miro/bestsellers-1998-2010/title&tag=miro/bestsellers-1998-2010/authoragain, producing:
{ "results": { "id": { "e7fee95f-4dcd-458b-8893-b56352d455cf": { "miro/bestsellers-1998-2010/author": {"value": "Dan Brown"}, "miro/bestsellers-1998-2010/title": {"value": "The Da Vinci Code"}} } } }In quite a few browsers, even the following will work:
http://fluiddb.fluidinfo.com/values?query=miro/bestsellers-1998-2010/rank=1&tag=miro/bestsellers-1998-2010/title&tag=miro/bestsellers-1998-2010/author
2. More interesting queries¶
Regular readers of this blog will recall that I previously published a rather larger set of 1,000 books to FluidDB. These were again originally from the Guardian (though pre-dated the data store/data blog) and this time consisted of the the Guardian’s 1,000 novels that everyone must read. (See this post and this post for details.)
So an obvious question is: which of that original Guardian 1,000 books are in the 100 bestsellers of the last 12 years? The following FluidDB query will tell you:
has miro/books/guardian-1000 and has miro/bestsellers-1998-2010/title
(If I’d picked my tags better, this query would have been even simpler, but it’s not bad.)
As an illustration, if I issue that query, again asking for author and title, I get the following (using fdb):
fdb show -q 'has miro/books/guardian-1000 and has miro/bestsellers-1998-2010/title' /about /miro/books/title /miro/books/author
7 objects matched
Object ce180ce3-29b5-4abc-a031-64015b162f6a:
/fluiddb/about = "book:birdsong (sebastian faulks)"
/miro/books/title = "Birdsong"
/miro/books/author = "Sebastian Faulks"
Object a2fa68ae-d409-422f-887a-dbdb7c1b4f18:
/fluiddb/about = "book:atonement (ian mcewan)"
/miro/books/title = "Atonement"
/miro/books/author = "Ian McEwan"
Object d5ff7995-2ae6-4ba8-8549-ea1d0726484c:
/fluiddb/about = "book:the kite runner (khaled hosseini)"
/miro/books/title = "The Kite Runner"
/miro/books/author = "Khaled Hosseini"
Object c64aeced-1505-4bb3-ab8a-0ce4c6a70ba3:
/fluiddb/about = "book:white teeth (zadie smith)"
/miro/books/title = "White Teeth"
/miro/books/author = "Zadie Smith"
Object 7e076540-3e14-4232-8c46-13863bae77ec:
/fluiddb/about = "book:the curious incident of the dog in the night time (mark haddon)"
/miro/books/title = "The Curious Incident of the Dog in the Night-Time"
/miro/books/author = "Mark Haddon"
Object 5be745bd-500d-458b-b4e6-dd08972b73f6:
/fluiddb/about = "book:to kill a mockingbird (harper lee)"
/miro/books/title = "To Kill A Mockingbird"
/miro/books/author = "Harper Lee"
Object 3b416fa5-51ab-4160-9820-240a0591c3a2:
/fluiddb/about = "book:the time travelers wife (audrey niffenegger)"
/miro/books/title = "The Time Traveler's Wife"
/miro/books/author = "Audrey Niffenegger"
(I’ve added some blank lines, but otherwise this is the raw output from fdb.)
Or perhaps I’d like to know all the books that sold over 2,000,000 copies. For that, the relevant FluidDB query is just:
miro/bestsellers-1998-2010/volume > 2000000
Again, illustrating with fdb, and this time asking only the for the about tag that FluidDB uses to identify the object, we get this (faintly depressing) list:
fdb show -q 'miro/bestsellers-1998-2010/volume > 2000000' /about8 objects matched
Object b2ff54a0-d94e-4fe1-951f-a4bd839ba219:
/fluiddb/about = "book:harry potter and the half blood prince childrens edition (j k rowling)"
Object e7fee95f-4dcd-458b-8893-b56352d455cf:
/fluiddb/about = "book:the da vinci code (dan brown)"
Object 04033298-9be8-41b8-b9ef-d1b11b1adfb9:
/fluiddb/about = "book:harry potter and the philosophers stone (j k rowling)"
Object 60c5bbea-2568-4a68-825f-ffc4cfb20f88:
/fluiddb/about = "book:harry potter and the prisoner of azkaban (j k rowling)"
Object 9258d0da-a65a-471b-abdb-277b68ea1ea0:
/fluiddb/about = "book:harry potter and the chamber of secrets (j k rowling)"
Object 04a4b407-7f21-450b-83c3-2d840ef6a133:
/fluiddb/about = "book:deception point (dan brown)"
Object 23d5a20a-ba28-43b8-9265-2afd8c4019ee:
/fluiddb/about = "book:twilight (stephenie meyer)"
Object 36bc89a5-d91c-4cdf-9389-ff2fbe833d59:
/fluiddb/about = "book:angels and demons (dan brown)"
3. Combining Data Sources¶
One of the things that is really interesting about this example is to look at the seven books that overlap. For example, Audrey Niffenegger’s wonderful book, The Time Traveller’s Wife is on both lists. A core idea of FluidDB is that different information comes to be associated by being placed on the same FluidDB object. The about tag (fluiddb/about) can be used to choose the object. In the case of novels, that object is identified [1] by an about tag of the form book:title (author)—in this case, book:the time travelers wife (audrey niffernegger). Obviously, there’s room for ambiguity with case and punctuation etc., but there’s a library and a website that will sort most of that out for you.
When I uploaded data on the Guardian 1000 books, (as the miro user) there wasn’t all that much information—author, title, year and the fact that it was on the Guardian 1000 list is pretty much all that was there. For example, here is what Aldous Huxley’s Brave New World looks like:

In the case of the best-sellers, the dataset contained a bit more information including sales volume, publisher, average selling prices and total sales value.
The marvellous thing is that books that are on both lists automatically get all the data from both sources, simply because they both chose the same FluidDB objects (e.g., the one with the about tag book:the time travelers wife (audrey niffernegger), which you can see live here in a modern browser), or as it is at the time I write:
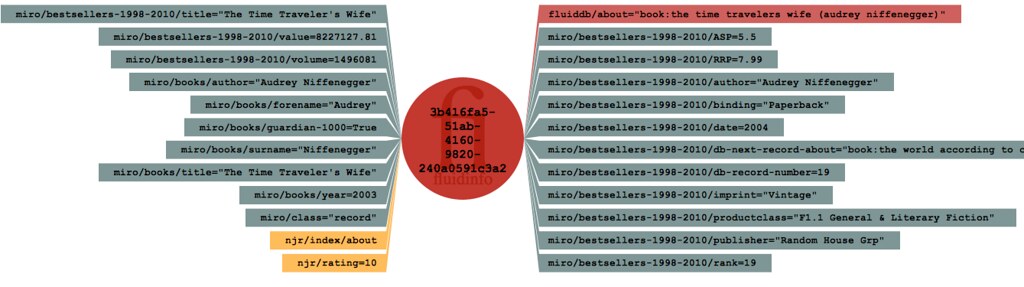
When I published the second list, I found that it included books that I had already rated in FluidDB. For example, I had already (personally, as njr) rated Small Island, by Andrea Levy, and as a result, when (as the miro user) I published the list of bestsellers, my njr/rating was already on some of them.
I think this is a powerful example of the potential of FluidDB, one that would be even more potent if it had been someone other than I (albeit as Miró) who had published to the at least one of two lists previously. But the point is, anyone following the convention about where to put data about books in FluidDB could equally easily have published the data with the same result. As usage of the system increased, we will see this more and more.
Go Explore; Go Tag¶
This post just scratched the surface, but I hope it begins to show the real and tangible benefits of publishing data to FluidDB. The data becomes capable of being queried. Multiple data sources combine, sometimes in ways that had not been foreseen. It can be accessed visually, from a command line, or programmatically. And you can add your own data, whether it be annotations, ratings, comments, associations or whatever.
So go explore; and if you like, get an account and start tagging/publishing.
| [1] | Regular readers will know that I am a rather strong advocate of conventions for about tags in FluidDB in general, and for this convention for books in particular. Anyone can publish any data to FluidDB using any objects or conventions they like; but, as this post illustrates, there are real benefits when different datasets concerning overlapping things use common conventions. |
Note the queries that end in '/Author' are broken... you need to use '/author' (lowercase) to get the expected result.
ReplyDeleteThanks, jkakar; I think I've fixed that now. Don't how they crept in . . . probably inadvertant applications of M-c in emacs :-(
ReplyDeleteIn your last example there is a lot of duplication of data. This is one of the things that I don't really like about FluidDB. With your example to find all books by audrey niffernegger you would need to use two different "author" tags in the query, I find that unacceptable. Surely there could be a standard global definition of "author"?
ReplyDeleteAnyone can add tags/data to an object, so as in your example, they will do. This will be in preference to finding an existing tag which contains the same information: maybe because you can control the permissions, maybe because you can't be sure that the tag actually has the same semantic meaning as yours (one person's surname tag could represent the authors name as of writing, the other's could change if say the woman author got married perhaps as a way of looking her up).
That is all well and good, but the point of FluidDB, as it seems to be being sold, is data interoperability. Well, there can never be any data interoperability unless there is a suitable specification for it. Systems using FluidDB which expect or allow others to interact with their data must specify their tag systems, otherwise it is pointless for anyone to try and use the data.
There are no explicit negative consequences of having disjoint data sets with duplicated data, but it doesn't make it easier to use multiple data sources and interact with them at all, it makes it more complicated.
I don't disagree with the principle of informal tag specification, arising from usage, because it does provide a very flexible system. However I can't see how you expect people to make decisions which will affect the whole FluidDB community. Thats said I can't think of a better alternative. (Maybe a standard library of tags??) Conventions *will* arise over time, probably when O'Reilly write a book about it...
Guy
ReplyDeleteYes, your point is well made. In this particular case, it's my own fault: since the data was written as the same user (miro) it should definitely have used the same tags, and in fact I do plan to update it so that it does. It will just be miro/book/author etc.
But the broader point you make is much more fundamental, and something I think about quite a lot. What I think will happen is that over time various FluidDB users will become recognized authorities on things and their tags will be used for preference. I imagine a situation where amazon.com is the recognized authority on Amazon prices, maybe isbn.org org is the main authority on authors, titles etc.
There could also be open tags. Maybe a 'wiki' user will emerge with all open write permissions allowing everyone and anyone to write the same tag.
I think there are pros and cons of the principle that everyone writes to his/her own namespace. Clearly, duplication and inconsistency are downsides, while diversity, responsibility, permissions etc. are upsides.
But it's an important issue.
Of course, one of the key distinguishing features of the about tag is that it *is* universal, so to the extent that we can agree on conventions for those (a major theme, if not the major theme of this blog) we can at least get data stored on the same object.
jmarques
ReplyDeleteHi. Sorry about that. I think there are two things going on here.
1. You will get extra failures with verbose on because a lot of the tests look at what gets sent to standard out and verbose causes extra stuff to get sent. So while it might be better if that weren't true, it isn't indicative of a real test failure.
2. I get the same as you with verbose on, and with verbose off, I get just a single failure:
======================================================================
FAIL: testUntagObjectByID (__main__.TestFluidDB)
----------------------------------------------------------------------
Traceback (most recent call last):
File "fdb.py", line 1123, in testUntagObjectByID
self.assertEqual(error, STATUS.NOT_FOUND)
AssertionError: 0 != 404
I'm pretty sure that's the result of a change to the API. Assuming that's right, clearly the test should change, but I need to double check that this is the case.
In the mean time, however, it looks to me as if the libraries performing exactly the same on your system as mine, and that should mean it actually works fine. I know that's a bit unsatisfactory, but I'll try to confirm the change, update the test and push the result to github in the next day or two. I'll blog when I do.
Regards
Nick
jmarques:
ReplyDeleteYes, it's as I thought. There was an API change that broke the test. I've just pushed version 1.28 to github and if you run that without verbose, everything should pass.
if you're interested, the change is documented at:
Deleting a tag instance now always returns 204
at
http://doc.fluidinfo.com/fluidDB/api/changelog.html#http-api-changes-2010-01-09